
One simple trick that statisticians hate
If you don't like the results, just ignore the control group

A delightfully suboptimal clinical trial was brought to my attention today. A sincere thanks to those responsible. I instantly noticed it was published in the American Journal of Gastroenterology, sending me on a trip down memory lane…
It was the earliest days of the COVID-19 pandemic and we were all hoping to find clues that might improve our response. The risk-factor farmers were out in force, and one such group published a pre-print strongly suggesting that the use of protein pump inhibitors (PPIs) might increase risk of COVID-19. But alas, even a cursory look into the results would quickly reveal concerns about the illegitimacy of the data, and several people took to twitter to share these with the authors (myself included, along with Mario Elia and Michael Johansen). Surely this would be a win for pre-prints and pre-publication peer review. After all, we had caught the flaws before the paper was finalized, surely sparing the authors any embarrassment or reputational damage. However, after raising these concerns with the senior author, he suggested that we “write a letter to the editor”, which was odd since he was in fact the editor. The damning critique was largely ignored and the paper was officially published shortly after, though they were at least kind enough to cite our letter of concern.
But enough about the past! Back to the #AmJGastro paper at hand. For those who want to play along, here is the link.
To summarize, this is a two-arm parallel randomized controlled trial of IBS patients, where one arm received a tailored 6-week diet plan based on an “AI” analysis of their gut microbiome, and the other received a 6-week diet plan based on the standard-of-care advice for this patient population. The key outcomes in the study were IBS symptom severity (IBS-SSS), anxiety, depression, and quality of life (IBS-QOL) measured at the end of the 6-week diet.
There are a number of issues with this trial, which I’ll get to, but the most important of these is that it is a textbook example of how to take a “null” trial and spin it to make it seem otherwise. They’ve accomplished this trick by conducting a 2-arm parallel RCT (smart!) but then analyzed it as if it was two single-arm studies (dumb!). The problems with this will be obvious to some, but because I see researchers doing this a lot, a refresher on basic experimental design is perhaps warranted before getting to the specifics of this trial.
Imagine a single-arm study where we expose patients to some new treatment. Given that we measured the outcome of interest before and after the treatment, and observed that patients tended to improve, should we conclude that the treatment worked? No! Of course not. Perhaps the improvement was due to the treatment, but maybe it was just the natural progression of the illness (a true improvement occurring with the passage of time), or regression to the mean (a statistical artifact masquerading as improvement).
In a single-arm study you have no way to isolate the causal effect of your treatment from these other factors, making it a very poor instrument for estimating said treatment effect. This is why we favor studies with active and control arms, where we allocate patients at random into each of them. By randomizing patients into two arms, you can expect that, on average, the resulting groups will have relatively similar baseline risks, similar disease progressions, and be similarly affected by any regression to the mean. Our estimate of the effect of the active treatment is then the difference in the average outcomes of the arms. This could be a difference in means, a risk ratio, etc. Then, if we do see a difference in outcomes between these groups, we should feel more confident that it’s specifically due to the difference in treatments they have received (e.g. a new drug vs current standard of care). If any of this is new to you, I have a 6 minute video on it here:
Following from the above, it’s critical to reemphasize that our estimates of treatment effects must be based on the between-arm difference in outcomes. However, many researchers ignore this and instead focus on the two within-arm (pre-post) differences. Anecdotally, this often seems to happen after failing to detect a “statistically significant” between-group difference.
For example, in the trial at hand, the top line result in the abstract is in fact a statistical test of the between-group difference, as it should be:
“For the primary outcome, there was a change in IBS-SSS of -112.7 for those in the PD group vs -99.9 for those in the FODMAP diet group ( P = 0.29)”.
We could get side-tracked on the subtly different ways we might interpret this, but however you slice it this is a null result - nothing about it should have us excited that the new, “personalized” approach to dietary advice is appreciably better than the FODMAP diet. It’s a “meh”, at best.
But apparently “meh” wasn’t good enough, because they follow this up in the abstract with a long list of the within-arm changes in outcomes and their associated statistical tests and p-values, even going so far as to note when an outcome significantly changed within one arm but not the other. This is the “trick” I see way too often. It’s when we minimize or ignore the valid between-arm estimate of the treatment effect of active vs control, and instead focus on the invalid estimates of treatment effects based on within-arm differences in outcomes over time, especially when one of these is “significant” and the other isn’t. To put this in the simplest possible terms, finding a “significant” change within one arm but not the other is not an excuse to ignore the “non-significant” between-arm difference. Please see Bland and Altman (BMJ, 2011) if you would like a more authoritative reference for this problem.
Table 2 from this trial actually makes this point better than I ever could. Across all outcomes, we see zero “significant” differences between arms (red), while pretty much every outcome improved “significantly” within both arms (blue).
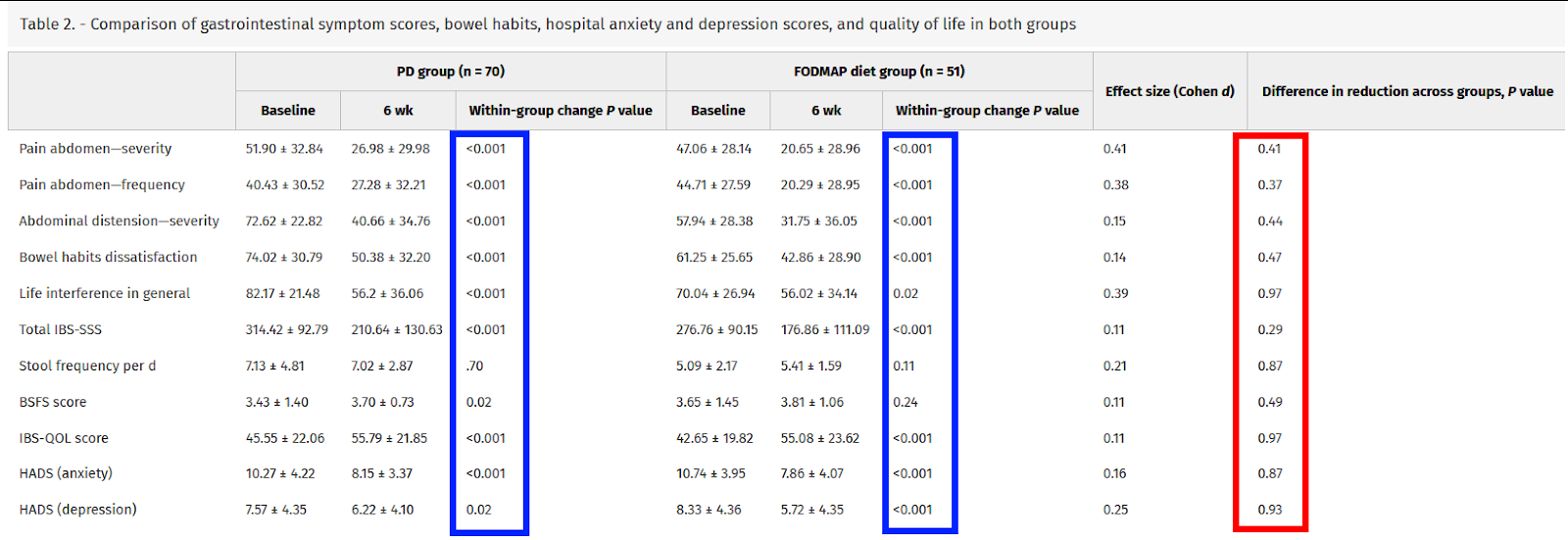
Table 3, however, is more entertaining, because they basically had to start drilling down to subscores to find the “one-arm significant but not the other” type results highlighted in the abstract, and focused on in the paper’s discussion.
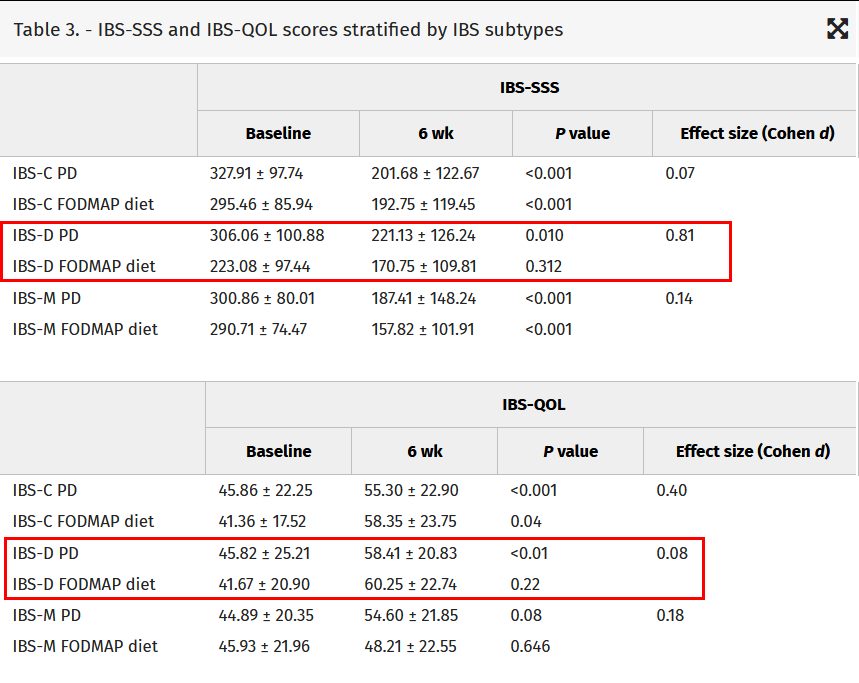
So if the clinical question is whether the microbiome/AI-personalized diet is appreciably better for patients than the current standard of care FODMAP diet, the actual answer surely lies somewhere between “probably not” and “we can’t tell from this trial”. But here is what they concluded:
The artificial intelligence-assisted PD emerges as a promising approach for comprehensive IBS management. With its ability to address individual variation, the PD approach demonstrates significant symptom relief, enhanced QOL, and notable diversity shifts in the gut microbiome, making it a valuable strategy in the evolving landscape of IBS care.
Clearly one could substitute “artificial intelligence assisted PD” with “FODMAP” and make the exact same conclusions, since the FODMAP diet was also associated with significant symptom relief, etc. And there is also nothing about these results evidencing the AI/microbiome guided diet’s “ability to address individual variation”, at least not in a manner that benefits patients. If anything, the conclusion is that addressing individual variation doesn’t seem to matter.
The only thing from the abstract I haven’t made note of yet are the “notable diversity shifts in the gut microbiome” associated with the AI guided dietary advice, but that’s because I was saving the “best” for last. You have to go to the supplement to get these results, but they are completely based on differences in “significance” in the within-arm tests. They don’t even bother to provide the between-arm comparisons, as they have done for the other outcomes.
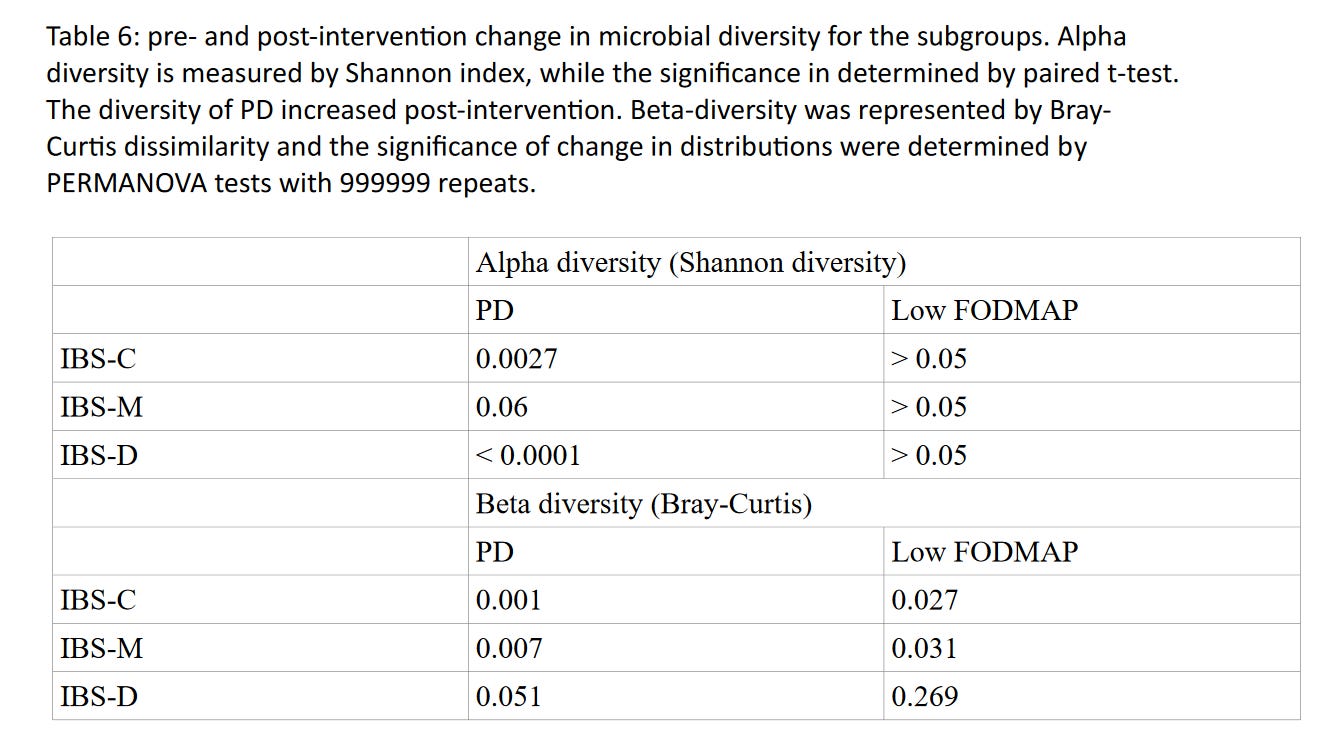
That said, let’s say that I’m happy to accept that the new diet impacted the gut microbiome differently than the FODMAP diet. Well…who cares!? In the world of clinical trials of medicines, where there are standards, we would call this a surrogate outcome (at best). It’s not to say that the gut microbiome doesn’t matter, far from it. It’s just saying that you and I are sitting here right now completely oblivious to the beta diversity of our gut microbiomes. It doesn't matter to us, except through how it might be impacting our actual lives. I have other opinions, but will leave them off for now.

Given that we have a conclusion that’s well out of line with the actual results, I did the super boring thing and checked conflicts of interest.

Great to see these declared. We often have to work with industry, and there are many excellent industry scientists that want the best for patients, so no complaints there. But I guess there is no harm in googling ENBIOSIS Biotechnologies.
Oh dear.

I wish this kind of thing was unusual, but it isn’t. I wish it wasn’t so dispiriting, but it is.
Postscript
To their credit, AmJGastro promptly published my letter with Tim Morris here outlining the concerns above. The authors actually took time to reply, but it was so nonsensical I almost felt sorry for them. Until of course I saw them using the publication of the trial to market their diet, further amplifying their lies about the results in the process. Incredible, but not surprising.

Finally, I said I cover a number of problems with this trial, but there is zero chance anyone has read this far anyway, so I’m just bullet-pointing these:
This was a two arm parallel RCT where the planned allocation was 1:1, meaning you should expect roughly the same number of patients in each arm. This kind of allocation is common, as it provides optimal power to detect effects and more precise estimates of effects (though there are reasons where you might favor another allocation, such as 2:1 etc but that’s not relevant here). Of course randomly allocating people with equal probability into two groups won’t guarantee a perfect split, so we often use what’s called a restricted randomization to help ensure a balanced allocation. One way of doing this is to randomize “blocks” of patients so that your allocation sequence is guaranteed to result in an equal number of allocations to each arm within each block. The authors state that they have indeed used a blocked randomization, but their block size is five. This is concerning, given what I just said, because the block size should then be a multiple of two, since it’s impossible to allocate five patients in equal numbers into the two arms, unless half-patients are a thing.
If you scroll down to the results, you will see they report a sample size calculation of 25 in each group. I’ll come back to how they arrived at this figure below, but it might at least provide an explanation for the block size, since 25 is divisible by 5 (?). However, that would in turn suggest that they were allocating 5 at a time into each arm, and that’s not really how you are supposed to do it.
From the text, “The study's sample size determination involved a power calculation based on an effect size of 0.8 (Cohen d), aiming for 80% power at a significance level (α) of 0.05 with an assumed SD of 100.” This is based on a between-arm difference in means, so is what you should expect for a 2-arm parallel RCT, and you would in fact get ~25 in each arm based on these inputs. What’s weird though is that despite a planned sample size of 50, they enrolled and randomized 149 patients. I guess it’s fortunate, since a larger sample results in more power and more precise estimates of treatment effects, but it warrants some explanation. It’s also a very large effect to power for, given the nature of the interventions and the subjective, highly variable outcomes. The results are what the results are, so what they planned for doesn’t really impact that after the fact, but it’s a red flag to plan so poorly.
Finally, while 149 patients were randomized, with 75 assigned to the PD group and 74 to the FODMAP diet group, 28 patients disproportionately withdrew from the study. Consequently, the final cohort included 121 patients, with 70 in the PD group and 51 in the FODMAP diet group. They note that this would adversely impact power (technically true) but wave away any concern about bias by noting “no statistically significant differences in demographic and clinical characteristics at baseline.”
Excellent. Very many social science/psychology studies are like this and worse. One memorable study that stays top of mind because it was so awful was on CBT for depression. It concluded by saying CBT was effective and should be considered the gold standard. However the paper itself stated that half the participants achieved nil outcomes and the other half minor or indeterminate. So much utter garbage gets published even in top journals and then thoroughly pollutes clinical practice.
Blocks of size 5? Planned sample size of 50 but randomized 149? Yikes! Some gems in that "I bet nobody read this far" bulleted list! (In all seriousness - great post!)